MON 3.1 - Ethique de l'intelligence artificielle - Explainable AI
- MON
- temps 3
- vert
- bleu
- débutant
- Emma Gonin
Un MON traitant de l'éthique de l'intelligence artificielle dans le secteur de la santé.
Prérequis
Aucun
Liens
- [1] Guide pratique IA éthique V2 France Hub IA
- [2] Un article super intéressant sur comment l'IA explicable peut bénéficier aux développeurs, aux cliniciens, aux patients du point de vue éthique et légal : Explainability for artificial intelligence in healthcare: a multidisciplinary perspective
- [3] Zahra Sadeghi et al., A review of Explainable Artificial Intelligence in healthcare
- [4] Survey of Explainable AI Techniques in Healthcare
- [5] Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV), Been Kim et al.
Je vais faire mon TFE sur un sujet combinant intelligence artificielle et développement web dans le secteur de la santé. Après les recommandations de Laetitia Piet, j'ai lu le livre blanc de France Hub IA sur lequel elle a travaillé, qui est un guide pratique sur l'éthique de l'Intelligence artificielle. [1]
Ce livre blanc énonce les 7 points clés de l'IA éthique :
- Sûreté
- Impact durable
- Autonomie
- Responsabilité humaine
- Explicabilité
- Equité
- Respect de la vie privée
Il y a de multiples utilisations de l'IA dans le domaine de la santé, pour n'en citer que quelques unes, la segmentation d'images médicales pour détecter une ou des tumeurs (mon sujet de stage), le suivi des signes vitaux d'un patient avec des dispositifs portés par le patient, l'automatisation de tâches répétitives effectuées par les médecins (création de rapports médicaux)... Des données sensibles sont utilisées pour entraîner ces IA, et la question de l'éthique est d'autant plus essentielle quant au traitement de ces données et des résultats fournis par les IA. Après avoir lu le livre blanc, j'ai décidé d'aller plus loin pour un des points énoncés ci-dessus : l'explicabilité. En effet, je me suis posée une question : Comment les praticiens (médecins...) et les patients, qui sont les utilisateurs finaux de l'IA, peuvent non seulement comprendre les résultats fournis par l'IA mais aussi croire à leur fiabilité ? Qu'est-ce qui prouve qu'une tumeur détectée par une IA sur une image médicale est vraiment une tumeur ? Quel fût le raisonnement de l'IA pour affirmer que ce qui est difficilement détectable par l'homme humain, est bien une tumeur ? D'ailleurs, à quel niveau d'incertitude affirme-t'elle l'existence de cette tumeur ? Nous allons voir dans ce MON quelques pistes pour décortiquer plus facilement la "boîte noire" (ou Black box) qu'est l'IA pour permettre aux utilisateurs finaux de comprendre.
Introduction
On peut distinguer deux types de modèles d'IA : ceux qui sont dit "interprétables", appelés également "white-box" et les autres qui sont dit "non-interprétables". Ce qui rend un algorithme interprétable est la clarté de la relation entre les données d'entrée et les données de sortie. Par exemple, les modèles de régression linéaire et les arbres de décision font partis des modèles interprétables : ils ont des caractéristiques claires qui expliquent l'influence des variables sur les résultats fournis par l'IA. En revanche, les modèles non-interprétables sont des structures complexes avec des poids, des paramètres qui sont inconnus ! Les algorithmes de Deep Learning font partis de ces "black-box models". Ils sont également sujets à des biais qui faussent les résultats et qui sont problématiques aux yeux des cliniciens.
Les recherches sur l'intelligence artificielle explicable ont explosé ces dernières années !
Challenges et limites de l'IA dite "opaque"
L'explicabilité des modèles d'IA est essentielle pour s'assurer que leur performance repose sur des données pertinentes et non sur des facteurs externes, comme des métadonnées. Un exemple célèbre est celui d'un modèle qui classait des huskies et des loups en se basant sur la neige en arrière-plan, plutôt que sur les animaux eux-mêmes. En médecine, un modèle d'IA utilisé pour détecter des patients à haut risque à partir de radiographies a échoué lorsqu'il a été testé en dehors de son hôpital d'origine, car il avait appris à identifier le type de machine utilisée plutôt que des informations cliniques pertinentes ! [2]
Il est important de mentionner les biais dans l'IA : l’ingénieur que j'ai interviewé souligne que l'IA peut être biaisée si elle est entraînée sur des données limitées ou homogènes (par exemple, provenant d'un seul hôpital). Ce type de biais pourrait affecter la capacité du modèle à généraliser à des cas réels et variés. La transparence d'une IA explicable permet de détecter en amont et comprendre ces biais, ce qui aide à ajuster les modèles pour éviter des erreurs cliniques.
Transparence, justifiabilité et intelligibilité : les maîtres-mots de l'intelligence artificielle explicable
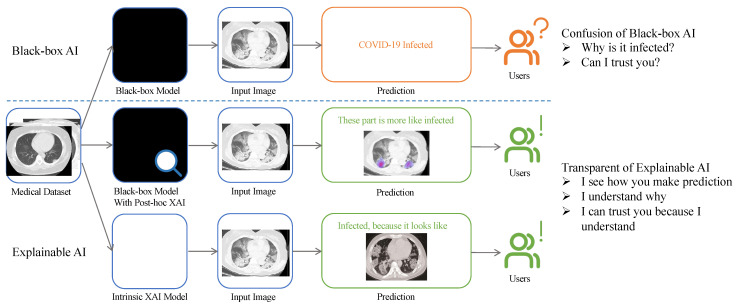
Cette figure provenant de cet article représente l'intérêt de l'IA explicable sur la détection d'une infection de Covid-19.
- Le premier modèle est une black box, l'utilisateur a juste en sortie le résultat "infecté" mais ne sait pas le pourquoi du comment. Le modèle est opaque et la confiance de l'utilisateur envers ce modèle chute.
- Le second output est une carte de chaleur qui montre les parties qui sont probablement infectées : l'utilisateur comprend et vérifie que les parties détectées par l'IA sont bien infectées, il sait où aller chercher l'information.
- Le troisième output est une comparaison entre la donnée d'entrée (input) et une donnée labelisée avec laquelle l'IA a comparé la donnée d'entrée. L'utilisateur alors peut avoir une confiance plus grande dans le résultat de l'IA.
Les cliniciens ne sont pas toujours intéressés par le fonctionnement technique de l'IA, mais veulent s'assurer que les résultats sont fiables. L'IA explicable permet aux cliniciens de comprendre sur quels critères le modèle se base pour prendre des décisions, renforçant ainsi leur confiance dans l'outil. En effet, l'explicabilité peut aider les cliniciens à évaluer les recommandations d'un système en les comparant à leur propre expérience et jugement clinique : cela leur permet de décider s'ils doivent ou non se fier aux recommandations du système et renforce ainsi leur confiance en celui-ci. En particulier, lorsque l'IA fait des recommandations qui diffèrent fortement des attentes du clinicien, l'explicabilité permet de vérifier si les paramètres pris en compte par le système sont pertinents d'un point de vue clinique.
Techniques de l'IA explicable
- Concernant les images médicales, des techniques telles que des cartes d'attention ou cartes de chaleur, qui mettent en valeur les régions de l'image qui ont le plus influencé la décision du modèle, sont utilisées pour augmenter la confiance des radiologues dans le résultat de l'algorithme. En effet, un ingénieur qui travaille dans le domaine médical nous raconte, dans une interview que j'ai mis en annexe, qu'"une carte de chaleur peut être utilisée sur les limites de la segmentation pour montrer l'incertitude dans les frontières [...]. Par exemple, pour les détections de tumeurs, cela permet aux cliniciens d'analyser plus de données provenant des résultats de l'IA et d'avoir un indice pour vérifier plus en détail où la tumeur pourrait se trouver. La variabilité des résultats est plus grande." Ces cartes de chaleur affinent le résultat et permettent peut-être à l'utilisateur final d'avoir une segmentation plus précise après un post-processing de l'image.
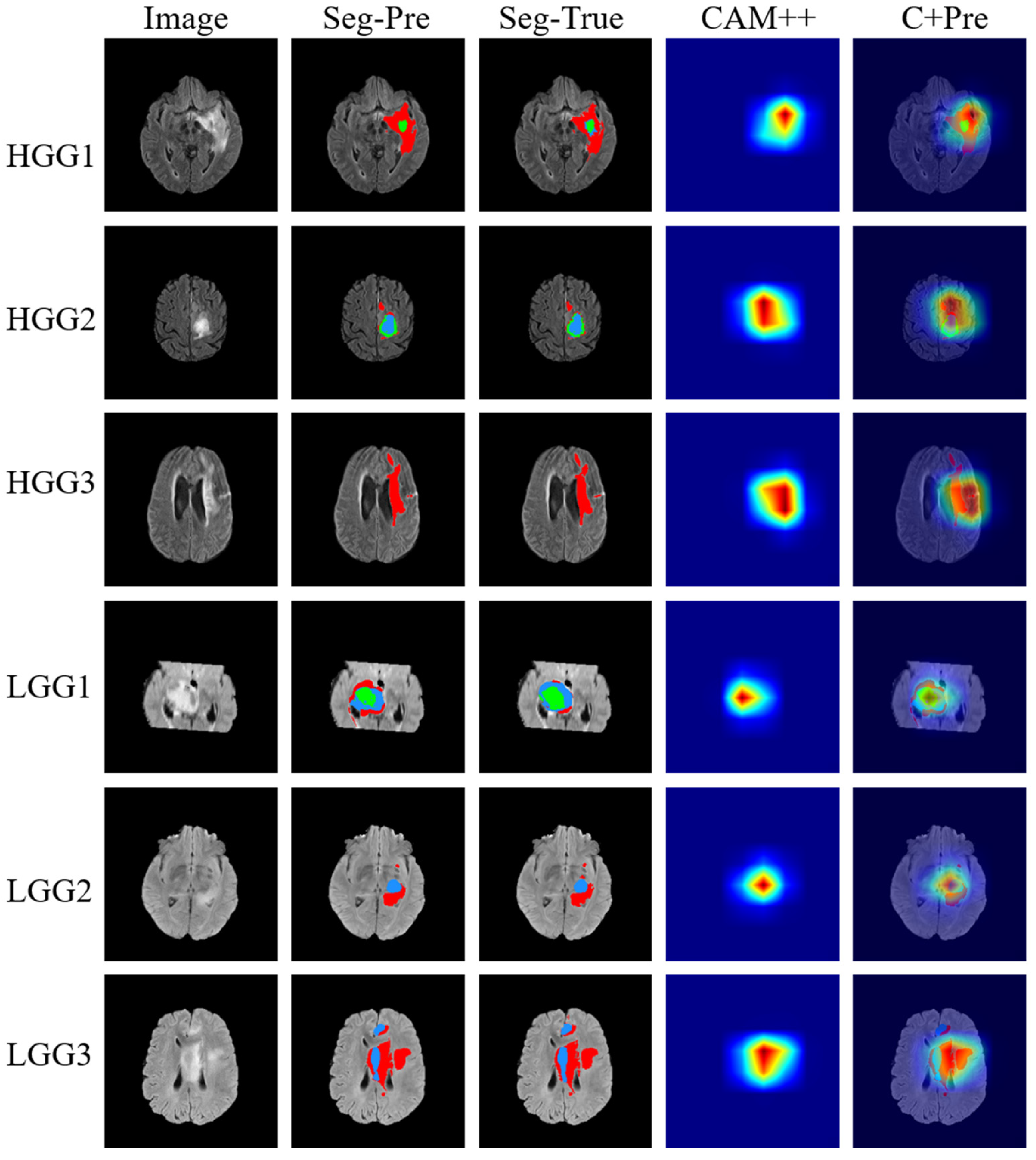
La figure ci-dessus inclut l'image originale, les résultats prédits par l'IA (Seg-Pre), la ground-truth (Seg-True) qui est l'image témoin considérée comme étant la vérité, une carte de chaleur qui représente les zones où s'est focalisé le modèle (CAM++) ainsi que la superposition des segmentations données par le modèle et les cartes de chaleur explicables (C+Pre). Concernant la carte de chaleur, le bleu indique que la prépondérence est faible tandis que le rouge indique que la zone a fortement contribué au raisonnement du modèle.
Pour expliquer le comportement interne d'un réseau de neurones avec une description compréhensible par l'humain, des Concept Activator Vectors peuvent être utilisés. [3]
 Les Concept Activator Vector d'un concept sont des vecteurs dans la direction des valeurs (par exemple les valeurs d'activation) des exemples du concept [5]. Les auteurs du papier [5] définissent un CAV tel que "la normale d'un hyperplan séparant les exemples sans concept et les exemples avec un concept dans l'activation du modèle". C'est un peu complexe mais je cite cet outil pour montrer qu'il existe des fonctions, des concepts, permettant de modéliser des modèles de Machine Learning complexes pour les rendre interprétables par un humain.
Les Concept Activator Vector d'un concept sont des vecteurs dans la direction des valeurs (par exemple les valeurs d'activation) des exemples du concept [5]. Les auteurs du papier [5] définissent un CAV tel que "la normale d'un hyperplan séparant les exemples sans concept et les exemples avec un concept dans l'activation du modèle". C'est un peu complexe mais je cite cet outil pour montrer qu'il existe des fonctions, des concepts, permettant de modéliser des modèles de Machine Learning complexes pour les rendre interprétables par un humain.Des librairies open-source ont été développées pour visualiser, débugger, analyser les biais des modèles de Machine Learning. En voici quelques noms :
- ELI5 sur Python pour visualiser et débugger les modèles de ML (développé par le MIT);
- AI Fairness 360 sur Python et R pour analyser et détecter les biais dans les modèles d'IA et les datasets (développé par IBM);
- What If Tool (WIT) pour visualiser les comportements de modèles de ML déjà entraînés (développé par Google);
- Skater analyse le comportement de modèles de ML déjà entraînés (développé par Oracle);
Dans le cas d'aide au diagnostic, des arbres de décisions peuvent expliquer pas-à-pas comment le modèle en arrive au diagnostic en fonction des symptômes du patient et de ses résultats.

Une image qui résume les différentes utilisations possibles de l'IA explicable dans la santé [3]
Conclusion
En conclusion, l'IA explicable dans le contexte médical vise à rendre les décisions de l'IA plus transparentes et compréhensibles, permettant aux cliniciens de vérifier et valider les résultats en s'appuyant sur leur expertise clinique. Cela renforce la confiance et aide à minimiser les risques associés à l'usage de l'IA en médecine. Je vous encourage à jeter un coup d'oeil aux articles que j'ai listé dans les sources ainsi qu'aux différents outils d'explicabilité pour avoir une idée de quel outil appliquer à votre modèle d'IA.
Annexe : Interview (VO en anglais) d'un ingénieur dans la recherche, qui travaille sur des modèles de machine learning dans le domaine de la cardiologie
_____ You are an engineer developping a platform that helps surgeons to plan a cardiac surgery (called Left Atrial Appendage Occlusion). You also have a master co-directed by 5 universities in Barcelona in Computer Vision. Can you tell us a bit more about the use of AI in your work ?
We do segmentations of the left atrial of the heart in order to get a 3D reconstruction to determine the size of occluder devices to treat atrial fibrillations-derived thrombus with a minimally-invasive intervention (called Left atrial appendage occlusion).
We use AI for these segmentations of medical images, I did my TFM (note from the interviewer : it's a master thesis in Spain) on that with the pipeline nnU-Net. It's a pipeline containing a pre-trained model for segmentations with pre-processing that reduce the need of hyperparametrisation, it's designed to work well with medical images like CT, MRIs...
We use another algorithm using Machine Learning to detect the position of the ostium (part of the heart) and the mitral valves on medical images.
We compute hemo-dynamics simulations manually, without AI. Well, a PhD student tried to predict the 4D MRI flows with AI but we do most of them by hand.
We also use ChatGpt and Copilot for coding as assistance-tools for error solving and making templates for problems that we encounter.
_____What type of data do you use to train the model ? How do you collect it ?
In my case, all the data was coming from the Hospital of Bordeaux. Around 100 cases were previously segmented by colleagues, the input data is DICOM then it's processed with Python librairies to transform it to NIFTI. They are 3D images : it's a series of images that represents a volume. Each one of these images is segmented and with the join of them, you can reconstruct a 3D segmentation or mesh.
_____Why do you have to convert the data to Nifti ?
It's just because the format is easier to handle ! DICOM is a folder with a lot of files while Nifti it's just a file that is compressed. Also, Totalsegmentator (note from the interviewer : it's a tool for segmentations using the nn-Unet method) accepts only Nifti data as input so that's why.
_____You work hand-to-hand with clinicians in this academical context. Are they familiar with how the AI models work ? How do you explain to them how it works ? (meetings ?)
I would say that there are two things : I didn't have to explain [how it works] because a clinician isn't interested in specifically how it works but only in the fact that it's working. In a segmentation, they see the result and check that the segmentation makes sense. In the case of an AI they have the tools to verify it. The AI can never take responsability of a medical decision, in any aspect from segmentation to diagnosis so they have to verify it themselves.
Well, explainable AI isn't mostly to explain how the AI works by itself but more on which the decisions it takes and on what things it's based to take the decision. You want to avoid the neural network to be a Black Box.
In the segmentation, the heatmap can be useful, for example a heatmap can be use on the borders to show the confidence in the borders because there are some irregularities. For exemple, for tumor detections, it allows the clinicians to analyse more data that come from the output of the AI and to have a hint to check in more details where the tumor could be. You have more variability in the output.
The literal result of the AI is always processed, the output layer usually have the threshold to simplify all the intermediate features to only give to the final user one simplified result.
_____For your TFM, you wanted to fine-tune a model, do you have an example of bias and tendencies in the data that could have affected the results ?
Yes, a lot. First of all, all the patients were from the same hospital. All the images came from the same machine while images from different machines could have had slightly different qualities... It would have make the AI potentially worst with inputs from other hospital. The contrast and other things used to emphasize the borders of the organ could be different and affect the results of the AI reasoning.
We had 300 medical images but only 100 of them were segmented. I realized when I analysed them that the ones that were segmented were the ones that were easier to segment. The human segmentators chose the easiest ones, that's logical but the AI is going to be worst for the images with more difficulty to segment, for example low contrasted images. The clinician can put contrast to detect in a more easy way the organ but if the image was acquired without contrast, the AI isn't used to detect the organ without color or contrast so the results would be bad.
I have to say that we shouldn't confound biais and intented fine-tuning. We can fine-tune a model with data of people from a similar demographics for specific reasons but you tend to aim for generalization.
_____Thank you so much for your time !
Annexe : Interview (la traduction en français) d'un ingénieur dans la recherche, qui travaille sur des modèles de machine learning dans le domaine de la cardiologie
_____ Vous êtes ingénieur et vous développez une plateforme qui aide les chirurgiens à planifier une opération cardiaque (appelée Occlusion de l'appendice auriculaire gauche). Vous êtes également titulaire d'un master codirigé par 5 universités de Barcelone en vision par ordinateur. Pouvez-vous nous en dire plus sur l'utilisation de l'IA dans votre travail ?
Nous effectuons des segmentations de l'oreillette gauche du cœur afin d'obtenir une reconstruction en 3D pour déterminer la taille des dispositifs d'occlusion pour traiter les thrombus dérivés des fibrillations auriculaires par une intervention mini-invasive (appelée occlusion de l'appendice auriculaire gauche).
Nous utilisons l'IA pour ces segmentations d'images médicales, j'ai fait mon TFM (note de l'interviewer : c'est une thèse de master en Espagne) sur ce sujet avec le pipeline nnU-Net. Il s'agit d'un pipeline contenant un modèle pré-entraîné pour les segmentations avec un pré-traitement qui réduit le besoin d'hyperparamétrage, il est conçu pour fonctionner correctement avec des images médicales comme les CT, les IRM...
Nous utilisons un autre algorithme utilisant l'apprentissage automatique pour détecter l'ostium (partie du cœur) et les valves mitrales sur les images médicales.
Nous calculons les simulations hémodynamiques manuellement, sans IA. Un étudiant en doctorat a essayé de prédire les flux de l'IRM 4D avec l'IA, mais nous faisons la plupart d'entre eux à la main.
Nous utilisons également ChatGpt et Copilot pour le codage en tant qu'outils d'assistance pour la résolution des erreurs et la création de modèles pour les problèmes que nous rencontrons.
_____Quel type de données utilisez-vous pour entraîner le modèle ? Comment les recueillez-vous ?
Dans mon cas, toutes les données provenaient de l'hôpital de Bordeaux. Une centaine de cas ont été préalablement segmentés par des collègues, les données d'entrée sont des DICOM puis elles sont traitées avec des librairies Python pour les transformer en NIFTI. Il s'agit d'images 3D : c'est une série d'images qui représente un volume. Chacune de ces images est segmentée et la réunion de ces images permet de reconstruire une segmentation 3D ou un maillage.
_____Pourquoi faut-il convertir les données en Nifti ?
Tout simplement parce que le format est plus facile à manipuler ! DICOM est un dossier avec beaucoup de fichiers alors que Nifti est juste un fichier qui est compressé. De plus, Totalsegmentator (note de l'interviewer : c'est un outil de segmentation utilisant la méthode nn-Unet) n'accepte que des données Nifti en entrée, c'est donc pour cela.
_____Vous travaillez en étroite collaboration avec des cliniciens dans ce contexte académique. Connaissent-ils le fonctionnement des modèles d'IA ? Comment leur expliquez-vous ce fonctionnement ? (réunions ?)
Je dirais qu'il y a deux choses : Je n'ai pas eu à expliquer [comment ça marche] parce qu'un clinicien n'est pas intéressé par la façon dont ça marche, mais seulement par le fait que ça marche. Dans le cas d'une segmentation, il voit le résultat et vérifie que la segmentation a un sens. Dans le cas d'une IA, il dispose des outils nécessaires pour la vérifier. L'IA ne peut jamais assumer la responsabilité d'une décision médicale, quel qu'en soit l'aspect, de la segmentation au diagnostic, et les médecins doivent donc la vérifier eux-mêmes.
En fait, l'IA explicable ne consiste pas principalement à expliquer comment l'IA fonctionne en elle-même, mais plutôt quelles sont les décisions qu'elle prend et sur quels éléments elle se base pour prendre ces décisions. Il faut éviter que le réseau neuronal ne devienne une boîte noire.
Dans la segmentation, la carte de chaleur peut être utile, par exemple une carte thermique peut être utilisée sur les limites de la segmentation pour montrer l'incertitude dans les frontières car il peut y avoir des irrégularités. Par exemple, pour les détections de tumeurs, cela permet aux cliniciens d'analyser plus de données provenant des résultats de l'IA et d'avoir un indice pour vérifier plus en détail où la tumeur pourrait se trouver. La variabilité des résultats est plus grande.
Le résultat littéral de l'IA est toujours traité, la couche de sortie dispose généralement d'un seuil permettant de simplifier toutes les caractéristiques intermédiaires pour ne donner à l'utilisateur final qu'un résultat simplifié.
_____Pour votre TFM, vous vouliez affiner un modèle, avez-vous un exemple de biais et de tendances dans les données qui auraient pu affecter les résultats ?
Oui, beaucoup. Tout d'abord, tous les patients provenaient du même hôpital. Toutes les images provenaient de la même machine, alors que les images provenant de machines différentes auraient pu avoir des qualités légèrement différentes... L'IA aurait été potentiellement moins bonne avec des images provenant d'autres hôpitaux. Le contraste et d'autres éléments utilisés pour mettre en évidence les contours de l'organe pouvaient être différents et affecter les résultats du raisonnement de l'IA.
Nous avions 300 images médicales, mais seules 100 d'entre elles ont été segmentées. En les analysant, je me suis rendu compte que les images segmentées étaient celles qui étaient les plus faciles à segmenter. Les segmentateurs humains ont choisi les plus faciles, c'est logique, mais l'IA sera moins performante pour les images plus difficiles à segmenter, par exemple les images faiblement contrastées. Le clinicien peut mettre du contraste pour détecter plus facilement l'organe, mais si l'image a été acquise sans contraste, l'IA n'est pas habituée à détecter l'organe sans couleur ni contraste, et les résultats seront donc mauvais.
Je dois dire qu'il ne faut pas confondre le biais et le réglage fin intentionnel. Nous pouvons affiner un modèle avec des données de personnes issues d'un groupe démographique similaire pour des raisons spécifiques, mais on a tendance à viser la généralisation.
_____Merci pour le temps que tu m'as accordé !